TL;DR
최근 카카오뱅크 사전과제 때 공부한 확률적 데이터 구조인 Count-Min Sketch를 사용했습니다.
기본
카카오뱅크에서 대규모 공채를 진행하고 있어서 Data Platform – Server Developer에 지원했습니다.
기본 설정에 대해 간략히 설명하십시오.
- 키워드 검색 (별도로 처리해야 하는 로직이 있지만 구현만 하면 되므로 중요하지 않음)
- 조회수 순으로 정렬된 키워드 목록
다음은 확률적 데이터 구조입니다. 카운트 최소 스케치사용 부분은 히트 수를 계산하는 데 사용됩니다.
이제 확률적 데이터 구조와 Count Min-Sketch를 살펴보겠습니다.
확률적 데이터 구조
채팅-gpt: 확률적 데이터 구조는 확률적 방법을 이용하여 많은 양의 데이터를 효율적으로 저장하고 처리하는 데이터 구조이다.
chat-gpt의 짧은 시놉시스를 보면 키워드를 고를 수 있다.
- 확률적 방법
- 많은 양의 데이터를 효율적으로 저장
확률적 방법
네 가지 확률적 데이터 구조인 hyperloglog, bloom 필터, cuckoo 필터 및 count-min-sketch를 보았습니다.
여기서 일반적인 아이디어는 해시를 사용하여 제한된 메모리를 사용하는 효과를 주는 것입니다.
그러나 해싱을 사용하는 경우 해시 충돌이 발생하여 정확한 값이 아닌 오류가 발생할 수 있습니다.
따라서 정확한 값이 아닌 근사치를 제공하고, 목표 오류율을 설정하고, 얼마나 많은 메모리를 보유하고 사용해야 하는지 확률적으로 결정합니다.
예
블룸 필터: 데이터가 이미 존재하는지 확인하기 위해 거짓 긍정을 허용하고 거짓 부정을 허용하지 않음
Count-Min Sketch: 빈도가 높은 상위 몇 개 항목을 찾을 수 있지만 빈도에 대한 정확한 값이 아니라 근사치입니다. (할당이 중요합니다.)
달성할 수 있는 이점
스토리지를 효율적으로 사용합니다.
- 특정 목적이 많은 데이터에 대해 수행되는 경우 메모리에서 수행할 수 있습니다.
- 기존의 결정론적 데이터 구조를 사용하고 메모리에서만 처리하기에는 데이터 양이 충분하지 않으면 메모리에 로드되지 않은 데이터에 대해 페이지 폴트가 발생하고 많은 시간이 소모됩니다.
카운트 최소 스케치
문제를 해결하다
헤비 타자 문제
- 전자 상거래 시스템에서 가장 많이 본 제품은 어제의 모든 제품 페이지 중 헤비급 선수그리고 그것을 찾아
- 검색 시스템에서 자주 검색되는 용어 헤비급 선수그리고 그것을 찾아
상위 K 문제
- 전자상거래 시스템에서 상단부터 K까지 상품을 검색합니다.
어떻게 작동합니까?
1. 너비가 3인 세 개의 int 배열을 준비합니다. (공간이 좁아 오류율이 높으나 편의상 생략한다.)
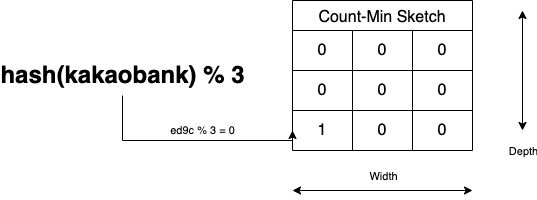
2. 키워드 ‘코코아 은행‘ 들어오면 Width로 mod 연산을 해서 결과 인덱스의 개수를 해시하고 늘립니다.
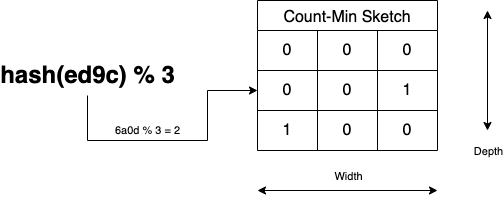
3. 이전과 같은 방법으로 이전 해시 값에서 카운트를 증가시킵니다.
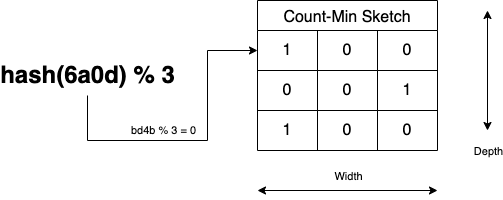
4. 마지막 정리도 같은 방법으로 합니다.
5. 이전과 같은 방식으로 들어오는 모든 입력 값을 계산합니다.
아래 링크에서 LIVE DEMO를 시도하는 것도 도움이 될 것입니다.
https://florian.github.io/count-min-sketch/#cms
당신이 맞습니까?
위의 내용을 다룰 때 가장 먼저 떠오르는 것은 해시 충돌로 인해 같은 숫자를 증가시키는 것은 너무 부정확하지 않습니까? 그것은 될 것이다.
위의 예에서 너비와 깊이는 임의로 3으로 설정하고 목표 오류율(ε, 무시할 수 있는 오차) 너비와 깊이를 설정합니다.
폭 = e/ε -> 전자 == 0.001 -> 약 2718 너비
깊이 = ln(1/δ) -> δ == 1^(-10) -> 약 23 깊이
이자형: 근사 오차
δ: 근사치가 오차 밖의 값이 될 확률(1 – δ는 근사값이 오차 내에 있을 확률입니다.)
(공식은 https://d2.naver.com/helloworld/799782 참조)
그러나 조치를 고려할 때 또 다른 문제가 있습니다.
실제 데이터가 모든 키워드의 동일한 빈도로 들어온다면 해시 값에 따라 CMS가 작동하는 방식이 다를 수 있지만 결과는 크게 다를 수 있습니다.
따라서 오류가 줄어 듭니다 롱테일 분포잘 작동
맞나요?
사전 할당에 포함되지 않은 요구 사항이 있습니다.
솔버가 상상으로 채울 수 있는 조건은 다음과 같다.
- 검색빈도
- 검색어의 카디널리티
- 검색 분포
위의 조건에서 사용 사례를 상상했습니다.
- 가끔 여행지에서 목적지를 찾는다.
- 사실 저는 여행을 잘 하지도 않습니다.
- 그들은 주로 근처의 카페나 유명한 식당을 찾습니다.
- 이 글을 읽는 사람이라면 누구나 근처 커피숍이나 유명 맛집을 찾아본 경험이 있다면 분포가 비슷하지 않을까 생각할 것이다.
- 검색에서 오타를 확인할 수도 있습니다.
- 검색어에 대한 제한이 없으므로 카디널리티가 큽니다.
따라서 카디널리티가 너무 커지면 Redis와 같은 캐시 서버에서 카운트하는 데 필요한 데이터의 양이 사용자 수가 증가함에 따라 증가합니다.
데이터가 클수록 해시 충돌로 인해 쿼리 시간이 길어집니다.
여러 Redis의 여러 노드에서 가장 큰 데이터를 정렬해야 하므로 각 노드에 필요한 순위를 쿼리해야 하므로 교차 샤드 쿼리가 발생합니다.
그 다음에..?

구현(WIP, 슬리피)
또 다른 진짜 문제
대략적인 순위는 일정 시간 내에 완료해야 합니다.
슬라이딩 윈도우
유명한 알고리즘인데 CMS에 적용해봐야겠네요.
마지막으로..
적합도가 합리적으로 동등하더라도 더 많은 사양을 만들어 악용되고 있습니다. 과잉 개발그렇지 않다고 생각합니다.
사전 귀속의 목적은 디자인의 디자인에 응모자의 경험과 지식이 어느 정도 활용되었는지를 판단하는 것이지만, 그 디자인은 응모자가 기대하는 디자인과 다를 수 있는 것 같습니다. (유연한 디자인, 사용성 및 확장성, MSA 경험, 코드 스타일 등을 고려했습니까?)
